
解决VLA模型落地难,普通硬件也能跑!全透明全开源的高效VLA模型把推理成本砍掉76%
发布日期:2026-05-05 06:33 点击次数:155
A₁ VLA团队 投稿
量子位 | 公众号 QbitAI
VLA模型的“动作头”正在拖垮机器人的反应速度?
A₁模型给出了教科书级的“瘦身”方案。

具身智能赛道正迎来关键破局点——Vision-Language-Action即“视觉-语言-动作模型”(简称VLA)。其已成为开放世界机器人操作的核心范式,但百亿级大模型backbone与迭代式动作头带来的计算成本高、实时性差,始终是落地在普通硬件上的致命瓶颈。
就在2026年4月,中山大学与MBZUAI联合推出A₁:一款完全开源透明、自适应高效的截断式视觉-语言-动作模型,不依赖私有数据与闭源组件,通过自适应推理实现低延迟、高成功率部署,实现推理成本大幅削减、实时控制低成本落地,彻底打破VLA模型“强性能=高开销”的困局。
A₁基于预训练视觉语言模型,提供动作生成所需功能性先验;核心采用预算感知自适应推理,监测中间层动作一致性实现提前退出,减少冗余计算。同时提出层间截断流匹配,以少量去噪迭代跨层热启动,联合加速主干网络与动作头。
实验表明,A₁在仿真与真实机器人平台上达到领先性能,推理时延最高降低72%,计算量最高减少76.6%。在RoboChallenge基准上,平均成功率29.00%,优于π₀、X-VLA等开源基线,兼顾效率与泛化能力。
VLA模型的真正瓶颈:不只是骨干大,动作头更卡
当前机器人VLA模型的结构很清晰:用视觉-语言模型(VLM)理解场景与指令,再用动作头输出连续机械控制信号。但这套流程藏着双重成本:主干VLM动辄数十亿参数,逐层推理耗时巨大;扩散/流匹配动作头需要10–20步迭代去噪,成为新的延时瓶颈。
即便有人优化了主干延迟,动作头依然拖慢全程,导致机器人反应慢、部署贵、难落地。
A₁的思路很干脆:算力只花在“能改变动作”的地方,多余计算全部砍掉。研究团队从三条关键观察出发,流匹配动作极少步即可稳定、连续动作冗余度高、中间层特征足够预测动作,基于这个核心思想,A₁实现了主干与动作头联合加速。
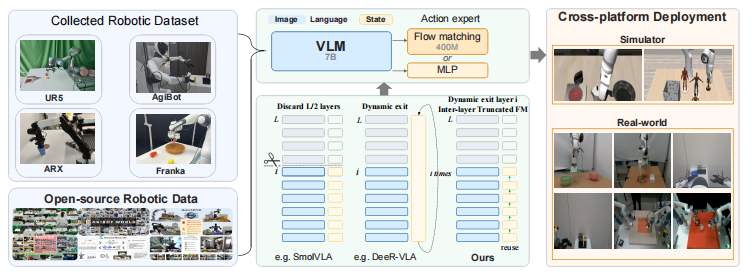
△ A₁模型整体架构
核心创新:自适应截断+层间流匹配,双管齐下提速
A₁以Molmo-7B为VLM主干,搭配流匹配或MLP两种动作头,真正拉开差距的,是它的自适应推理引擎。
1. 动作一致性提前退出:算到“够用”就停
训练时,A₁让VLM每一层都接入共享动作头,同步学习。推理时则逐层输出动作,一旦相邻层动作差异足够小,就直接终止前向传播,让模型自主判断推理深度,大幅砍掉冗余计算。
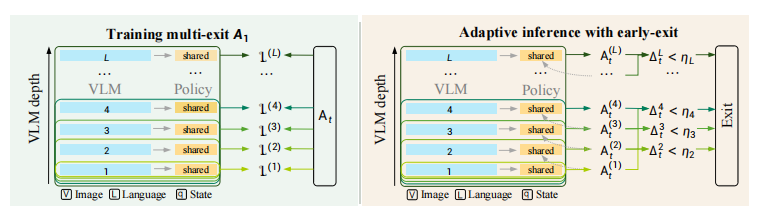
△ 训练与自适应推理流程
2. 层间截断流匹配:解决动作头越加速越慢的悖论
传统提前退出会让流匹配动作头重复去噪,越加速越慢。A₁提出层间截断流匹配,压缩去噪步数,并让上一层结果作为下一层热启动值,不再从随机噪声重新开始,把动作头迭代成本压到较低水平。
3. 多机器人泛化预训练:开源数据也能训出强模型
A₁采用两阶段训练,先用公开机器人数据集大规模预训练,再用自研真机轨迹做领域适配,配合数据增强与均衡采样,快速适配不同机械臂平台,不靠私有数据也能实现强泛化。
效果落地:仿真稳、真机强、开源第一
A₁的优势不只是理论高效,在仿真与真实机器人上都交出了亮眼成绩。
在仿真环境中,它在经典基准上保持极高成功率,同时推理速度大幅提升,实现做得更准,算得更快。
真正的考验在真实机器人。A₁在Franka、AgiBot、OpenArm、Dobot-Arm多款设备上完成抓取、摆放、整理、擦拭等任务,整体表现明显优于主流开源模型。尤其在长时段任务与小样本学习上,A₁动作更稳定、误操作更少。
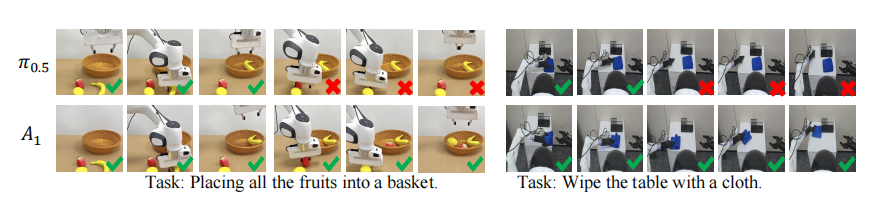
△ 长时序任务执行对比图
在权威的RoboChallenge真机测评中,作为完全开源、全栈可复现的方案,A₁超越多款知名基线,在开抽屉、精准放置等关键任务上表现突出。

△ 自适应推理可视化

△ A₁成功部署于自研OpenArm双臂移动平台,支持高精度操作

△ AgiBot真机早停可视化
这才是未来:高性能≠高成本
A₁最有价值的地方,是它重新证明:机器人VLA模型不必堆参数、烧算力。
它用自适应截断机制实现三大突破:全链路同时加速主干与动作头、按任务复杂度动态分配算力、全栈开源透明可复现。这让机器人控制大模型终于可以走出昂贵机房,落到普通硬件上,大幅降低实时控制与多机型适配的门槛。
下一步:更通用、更精准、更流畅
A₁的出现,让具身智能从“实验室炫技”真正走向低成本、可落地、全透明的实用阶段。当VLA模型不再被算力绑架,机器人走进日常场景的脚步,无疑会大幅加快。在VLA模型越来越卷参数的今天,A₁提醒我们:好的机器人智能,不是算得更多,而是算得更准、更省、更有用。
目前A₁论文、代码、模型权重已全面开源,欢迎感兴趣的研究者复现体验。
打开新闻客户端 提升3倍流畅度打开新闻客户端 提升3倍流畅度打开新闻客户端 提升3倍流畅度打开新闻客户端 提升3倍流畅度论文标题:
A₁: A Fully Transparent Open-Source, Adaptive and Efficient Truncated Vision-Language-Action Model
论文链接:
https://arxiv.org/abs/2604.05672
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
我们正在招聘一名眼疾手快、关注AI的学术编辑实习生 🎓
感兴趣的小伙伴欢迎关注 👉 了解详情

🌟 点亮星标 🌟
科技前沿进展每日见


京东外卖官宣:全年0佣金,启动“品质堂食餐饮商家”招募

4月北京二手房网签1.56万套
10天破30亿,2025年贺岁档已超去年总票房
震裕科技:2025年年度归属于上市公司股东的净利润同比增长1
美联储理事:贸易政策已影响经济 当前利率处于良好位置
美元因“数据断供”持续承压,欧元正暗中蓄势待发?

